Abstract
Concealing malicious components within widely used USB peripherals has become a popular attack vector utilizing social engineering techniques and exploiting users’ trust in USB devices. This vector enables the attacker to easily penetrate an organization's computers even when the target is secured or in an air-gapped network. Such malicious concealment can be done as part of a supply chain attack or during the device manufacturing process. In cases where the device allows the user to update its firmware, a supply chain attack may involve changing just the device's firmware, thus compromising the device without the need for concealment. A compromised device can impersonate other devices like keyboards in order to send malicious keystrokes to the computer. However, the keystrokes generated maliciously do not match human keystroke characteristics, and therefore they can be easily detected by security tools that are designed to continuously verify the user's identity based on his/her keystroke dynamics. In this paper, we present Malboard, a sophisticated attack based on designated hardware concealment, which automatically generates keystrokes that have the attacked user's behavioral characteristics; in this attack these keystrokes are injected into the computer in the form of malicious commands and thus can evade existing detection mechanisms designed to continuously verify the user's identity based on keystroke dynamics. We implemented this novel attack and evaluated its performance on 30 subjects performing three different keystroke tasks; we evaluated the attack against three existing detection mechanisms, and the results show that our attack managed to evade detection in 83–100% of the cases, depending on the detection tools in place. Malboard was proven to be effective in two scenarios: either by a remote attacker using wireless communication to communicate with Malboard or by an inside attacker (malicious employee) that physically operates and uses Malboard. In addition, in order to address the evasion gap, we developed three different modules aimed at detecting keystroke injection attacks in general, and particularly, the more sophisticated Malboard attack. Our proposed detection modules are trusted and secured, because they are based on three side-channel resources which originate from the interaction between the keyboard, user, and attacked host. These side-channel resources include (1) the keyboard's power consumption, (2) the keystrokes’ sound, and (3) the user's behavior associated with his/her ability to respond to displayed textual typographical errors. Our results showed that each of the proposed detection modules is capable of detecting the Malboard attack in 100% of the cases, with no misses and no false positives; using them together as an ensemble detection framework will assure that an organization is immune to the Malboard attack in particular and other keystroke injection attacks in general.
Prediction of wastewater treatment quality using LSTM neural network
Authors: Nitzan Farhi, Efrat Kohen, Hadas Mamane and Yuval Shavitt
Abstract
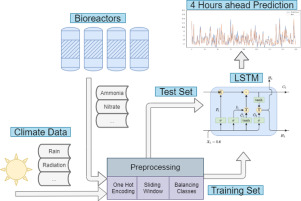
Wastewater treatment (WWT) process is used to prevent pollution of water sources, improves sanitation condition, and reuse the water (mostly for agricultural purposes). One of the main goals of wastewater treatment is removal of nutrients, such as nitrogen which exists in the form of ammonia in the sewage. Excessive nitrogen concentration in the effluent is well known for eutrophication in aquatic environments and may cause a decrease of groundwater quality as a result of irrigation. However, it is not uncommon that the biological process results with undesirably high concentrations of nutrients, and therefore Wastewater Treatment Plants (WWTP) monitor nutrients to alert operators of this problem. It is desirable to identify WWT problems in the process ahead in order to achieve a better treatment. Thus, we suggest a novel machine learning method, based on Long-Short Term Memory (LSTM) architecture, that is able to predict effluent concentration of ammonia NH
and nitrate NO
a few hours ahead. We used measurements from the biological reactors sampled every minute, and combine it, for the first time in the literature, with climate measurements for improved prediction accuracy. Our proposed method showed an accuracy rate of 99% and F1-Score of 88% when predicting ammonia concentrations and an accuracy rate of 90% and F1-Scoreof 93% when predicting nitrate concentrations.
Prediction of full scale WWTP’s Activated Sludge’s SVI test using LSTM Neural Network
Authors: Efrat Kohen, Nitzan Farhi, Hadas Mamane and Yuval Shavitt
Year: 2022
Publisher: Environmental Science: Water Research & Technology
Abstract
Wastewater treatment (WWT) is a process used to remove contaminants from wastewater, prevent pollution of water sources and improve sanitation conditions. The treated effluent is reused mostly for irrigation purposes which reduces the growing global demand for clean water. Sludge separation is considered one of the main problems in activated sludge (AS) systems. Most separation problems are related to the characteristics of the activated sludge floc and the content of filament organisms. Two main key parameters to control and prevent separation problems are to conduct a sludge volume index (SVI) test and microscopic observations. In this study we used data from Shafdan, which is the largest wastewater treatment plant (WWTP) in Israel, for predicting the future value of the SVI. Recurrent neural networks (RNNs) are a class of artificial neural networks (ANNs) for processing sequential data. Long short term-memory (LSTM) neural networks are a specific kind of RNNs that are capable of learning long-term dependencies and have achieved state-of-the-art results. Our proposed bidirectional LSTM model shows an accuracy rate of 89% and an F1-score of 82% when predicting high SVI results a few days ahead, by using a window size of 5 days.
Detecting Security Patches via Behavioral Data in Code Repositories
Authors: Nitzan Farhi, Noam Koenigstein and Yuval Shavitt
Year: 2023
Presented at: The AAAI-23 Workshop on Artificial Intelligence for Cyber Security (AICS)
Abstract
The absolute majority of software today is developed collaboratively using collaborative version control tools such as Git. It is a common practice that once a vulnerability is detected and fixed, the developers behind the software issue a Common Vulnerabilities and Exposures or CVE record to alert the user community of the security hazard and urge them to integrate the security patch. However, some companies might not disclose their vulnerabilities and just update their repository. As a result, users are unaware of the vulnerability and may remain exposed. In this paper, we present a system to automatically identify security patches using only the developer behavior in the Git repository without analyzing the code itself or the remarks that accompanied the fix (commit message). We showed we can reveal concealed security patches with an accuracy of 88.3% and F1 Score of 89.8%. This is the first time that a language-oblivious solution for this problem is presented.